ECTC 是先进封装领域首屈一指的会议,在会上会讨论一些先进封装领域我们最喜欢的一些主题,例如混合键合、共同封装光学器件等。还有一些交易和供应链细节,我们也可以专门详细介绍与这些主题相关的内容。
今年有,笔者参加了 2022 年 IEEE 第 72 届电子元件和技术会议。在这里,我们将讨论的重点包括台积电的 CoWoS-R+、台积电的第四代 SoIC(3 微米间距混合键合)、英特尔和 CEA-LETI 自对准集体(collective)裸片到晶圆混合键合、三星对包括混合键合在内的monolithic vs MCM vs 2.5D vs 3D 的研究。以及SK海力士、美光和联发科等在先进封装方面的研究。
台积电的 CoWoS-R+
台积电并没有止步于 CoWoS R,CoWoS-R+ 在这项技术上不断发展。

要理解的关键概念之一是die-to-die连接的距离。HBM 是目前将AI 和高性能计算的内存带宽提高到合理水平的唯一方法。随着最初的 HBM 以每个pad 1Gbps 的速度出现,现在的HBM2 和 HBM2E 一代迅速增长到 2.4Gbps 和 3.2Gbps。HBM3 将一路达到 6.4Gbps。封装宽度也从 HBM2 的 7.8mm 增长到 HBM2E 的 10mm 到 11mm,这意味着互连长度现在增长到大约 5.5。
简而言之,“线”需要传输更快的数据速率,同时还要走更长的距离。这是非常难以做到的,并且会产生大量噪声,从而降低信号完整性。
另一个问题是,随着摩尔定律的放缓与日益增长的性能需求作斗争,芯片的功率正在爆炸式增长。Nvidia 的 Hopper 已经拥有 700W的功率,但未来封装将激增至千瓦级。HBM3 也比 HBM2E 更耗电。通过封装的更多功率也可能会产生更多噪声,从而降低信号完整性。
台积电开发了一种新的高密度 IPD 来解决这个问题。简而言之,台积电客户可以在 CoWoS R+ 上实现 6.4Gbps HBM3,但在 CoWoS R 上却不行。高密度 IPD 对于增加额外电容以平滑供电很重要。如Graphcore 就是在使用台积电的SoIC混合键合之后,在不大幅提高功耗的情况下,将产品的时钟提升了40%。
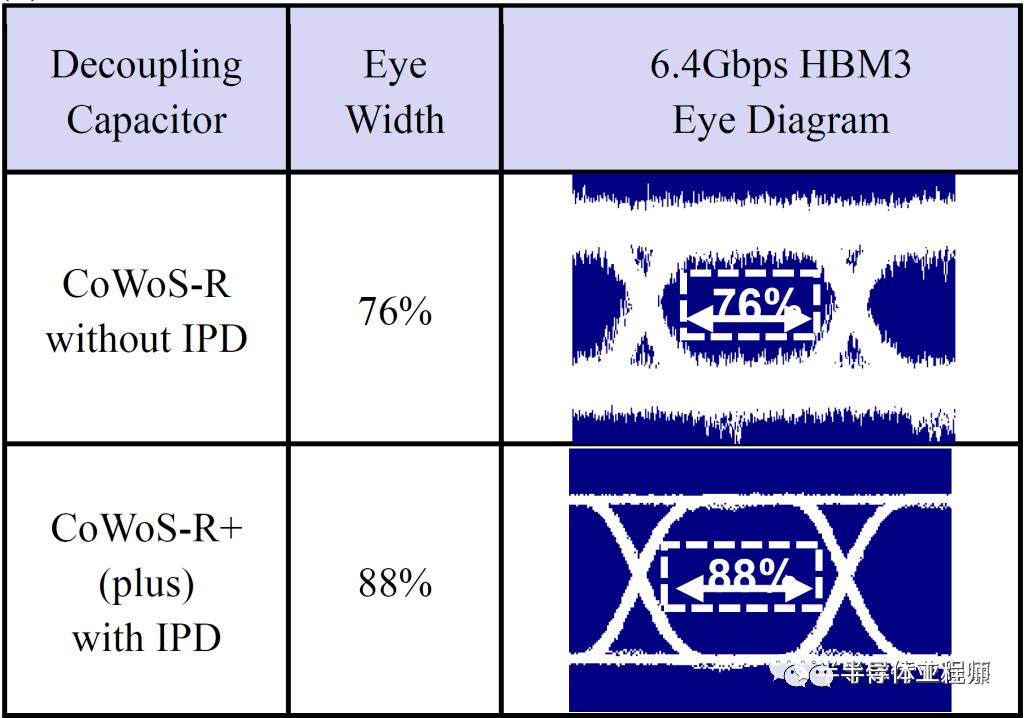
台积电还分享了mbedded bridge die的更多发展。该桥与顶部有源芯片之间的互连可以降至 24 微米。台积电现在可以实现与 CoWoS-S(全无源硅中介层)相匹配的 3 倍reticle限制。未来,他们的路线图将达到 45 倍reticle尺寸,这意味着使用chip last工艺的复杂芯片可用于晶圆级封装。与此同时,CoWoS-S 仅在明年扩展至 4 倍。
台积电第 4 代 SoIC,实现 3 微米间距混合键合

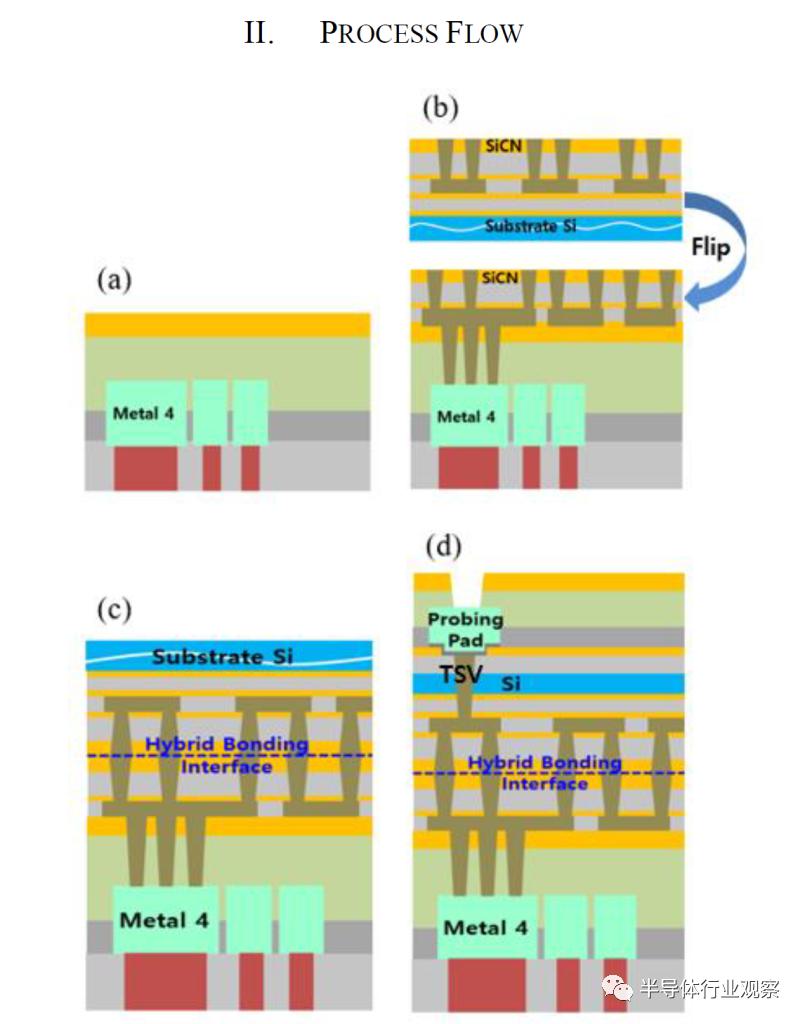
台积电的混合间和的过程大致相同。他们从完成的晶圆开始,形成一个新的bonds pad,蚀刻它,沉积一个seed层,电镀。接下来,他们对顶部die晶圆进行减薄和切割。特别注意保持它们的清洁。完成等离子激活,并粘合die。
台积电的论文展示了 SoIC 的良率,这非常有趣。这是在尺寸为 6mm x 6mm 的测试裸片上使用菊花链测试(daisy chain test )结构,这和 AMD 的 V-Cache 的裸片尺寸一样方便。
晶圆上芯片(chip on wafer )混合键合中最慢的步骤之一是——BESI 工具物理地拾取die并将其放置在底部晶圆上。这个绑定步骤严重影响准确性,吞吐量与准确性是一场非常大的战斗。具有 3 微米 TSV 间距的台积电展示的良率没有差异,电阻在小于 0.5 微米的未对准时没有显着变化,键合良率达到 98%。
从 0.5 微米到 1 微米,它们的良率确实提升了了,但它们的菊花链结构的最后 10% 的电阻急剧增加。间距大于 1 微米,它们的良率为 60%,所有测量的结构都超过了它们的电阻规格。0.5 微米是一个非常重要的水平,因为 BESI 声称其 8800 Ultra 工具的精度小于 200 纳米,尽管我们听说它更像是 0.5 微米,具有很大的差异,即使吞吐量是工具额定规格的一半。
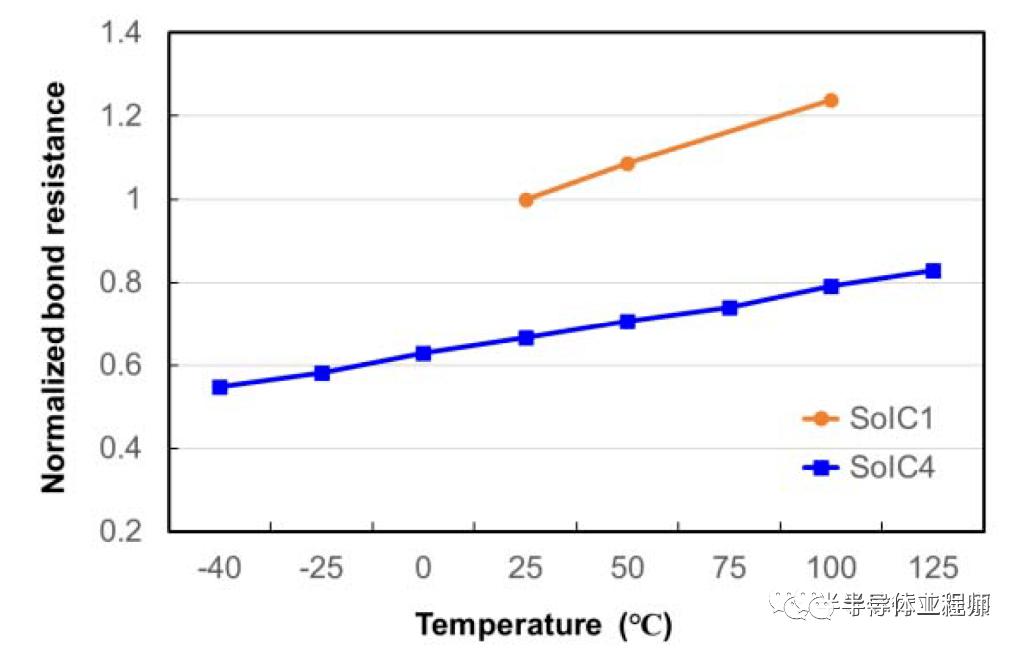
台积电还展示了更薄的阻挡层(thinner barrier layer),这也让整个堆栈的接触电阻(contact resistance)更好。此外,台积电认为 SoIC 更可靠。这包括更广泛的工作温度范围。但当 AMD 完全在其 5800X3D 台式机芯片上锁定超频和修改功率时,许多人感到失望。这可能只是第一代的一个小问题。由于 TSMC 的 Cu 合金进行了改进,并且随着 SoIC gen 4 间距减小,它们似乎正在提高其可靠性和良率。
英特尔和 CEA-LETI的Collective Die to Wafer混合键合
英特尔和 CEA-LETI 将Collective Die to Wafer与自对准技术相结合,实现了 150 纳米的平均未对准(mean misalignment,比die to wafer更准确)并具有更高的吞吐量。自对准技术非常酷。他们利用水滴的毛细作用力在修改后的拾取和放置工具将其快速但不太准确地放置在所需位置后使对齐更加准确。随着水的蒸发,产生直接键合,无需任何其他中间材料。然后,键合晶片进入标准退火步骤,加强键合。
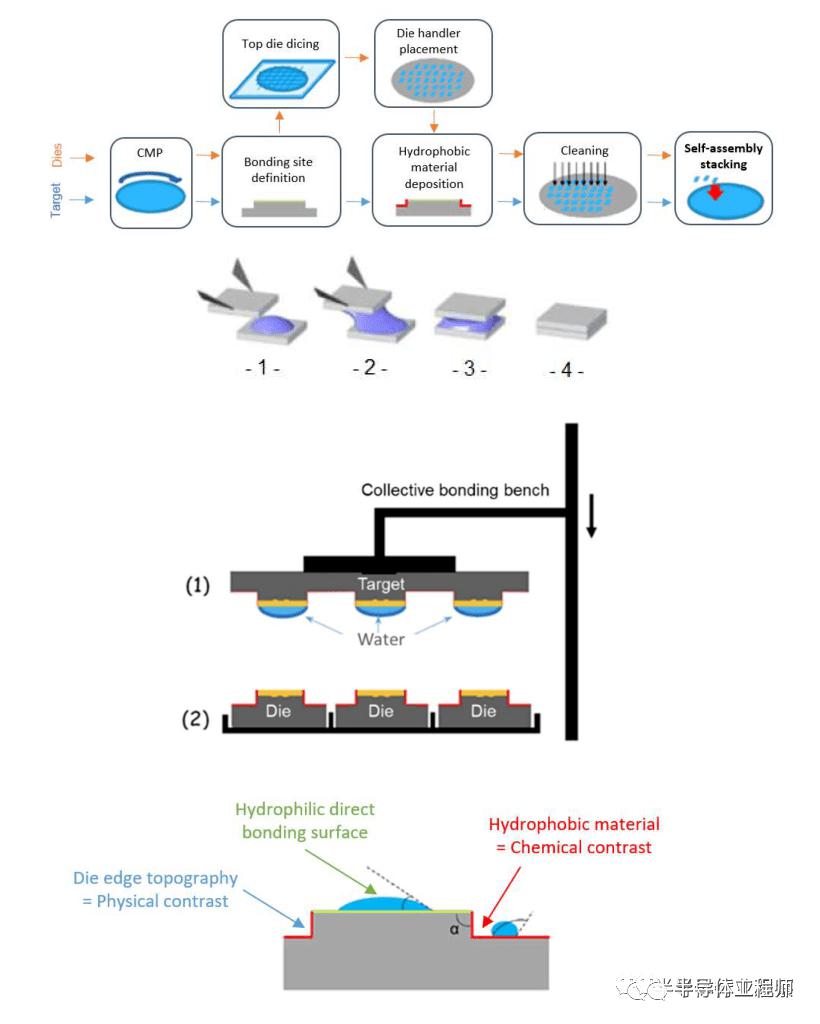
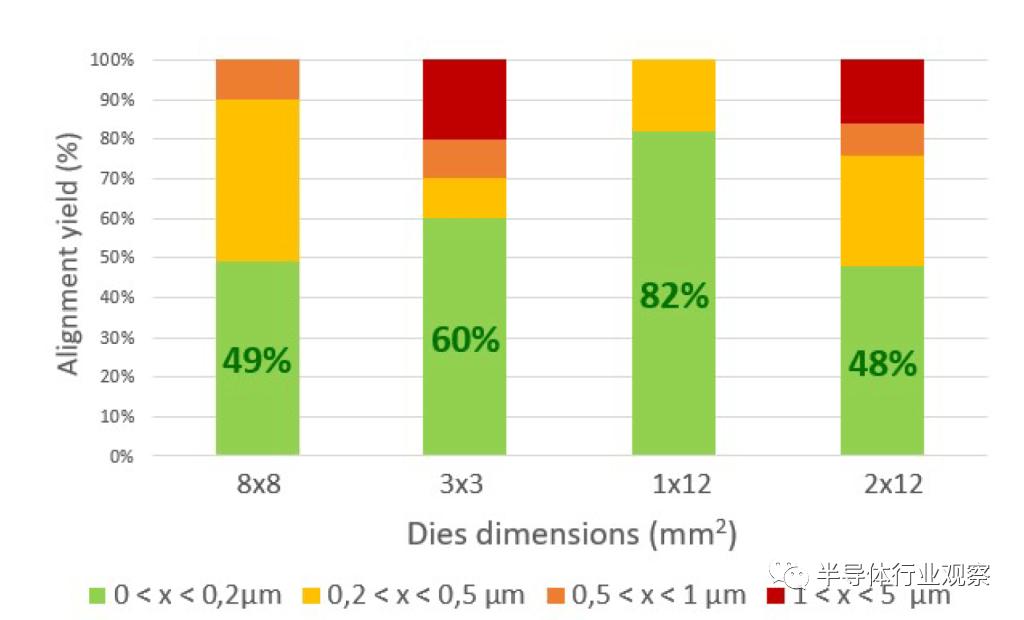
除了水滴沉积(water droplet )之外,唯一独特的步骤是在粘合部位应用亲水和疏水材料,这可以用纳米覆盖精度进行光刻定义。这不是一个没有问题的过程。有许多与分配水、液滴特性、冷凝和粘合过程有关的问题。英特尔和 CEA-LETI 以 3 个指标展示了结果。Collection Yield是指在die上捕获的水滴。Bonding yield 是指成功键合的dies数量。Alignment yield是指具有亚微米精度的die数量。
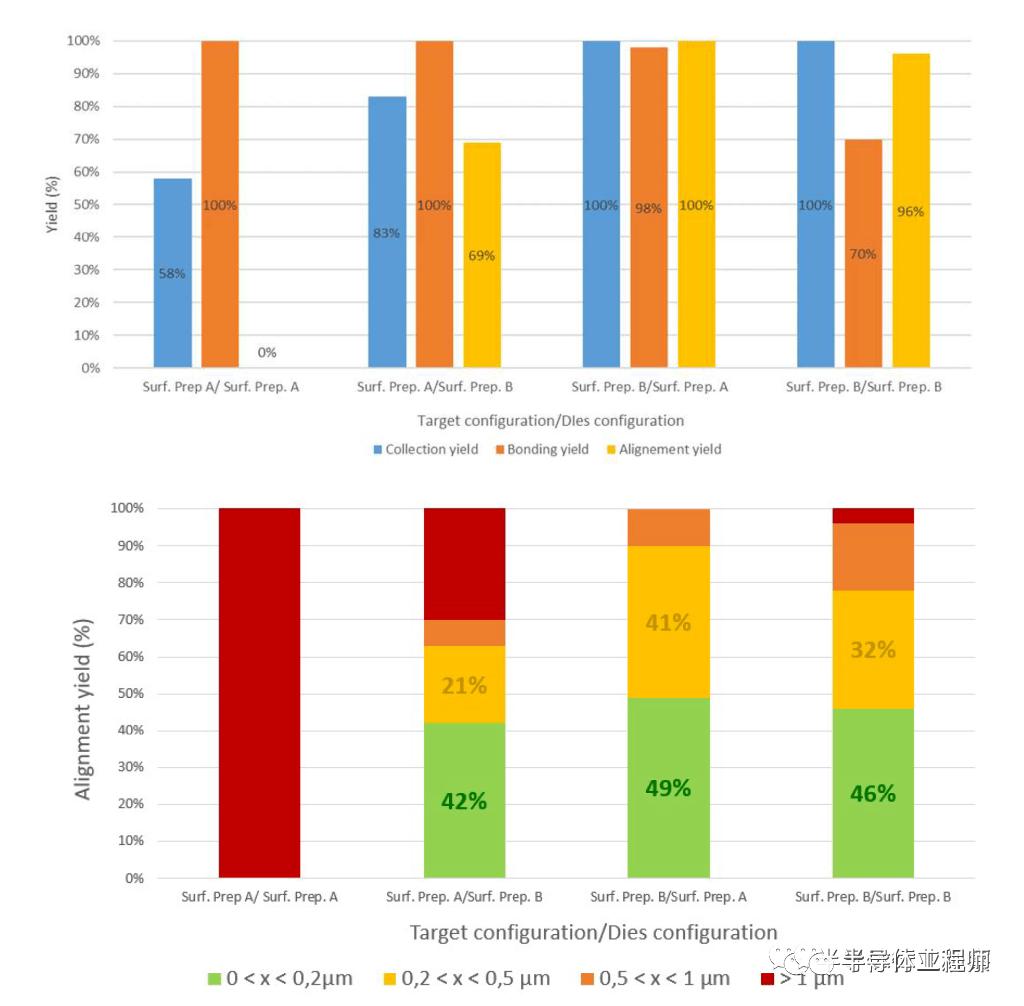
他们尝试了各种工艺的矩阵,其最好的方法实现了 98% 的bond yiled和 100% 的其他步骤。总对准精度令人惊叹,所有die的对准精度都低于 1 微米,大多数die的对准精度低于 0.2 微米。英特尔和 CEA-LETI 尝试使用多种不同的die尺寸实现这一点,这个过程在非常高的纵横比die上非常出色,这非常有趣。
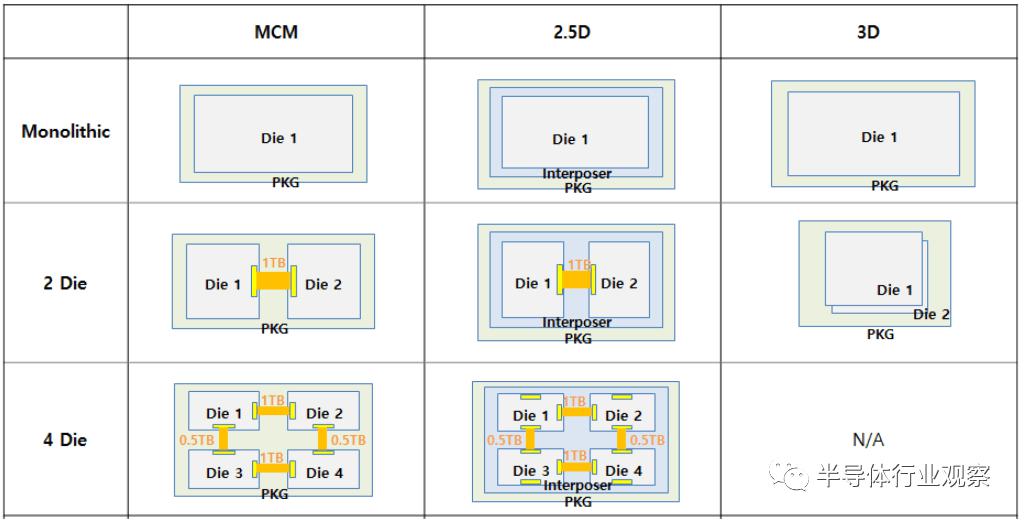
三星 Monolithic vs MCM vs 2.5D vs 3D,包括混合键合
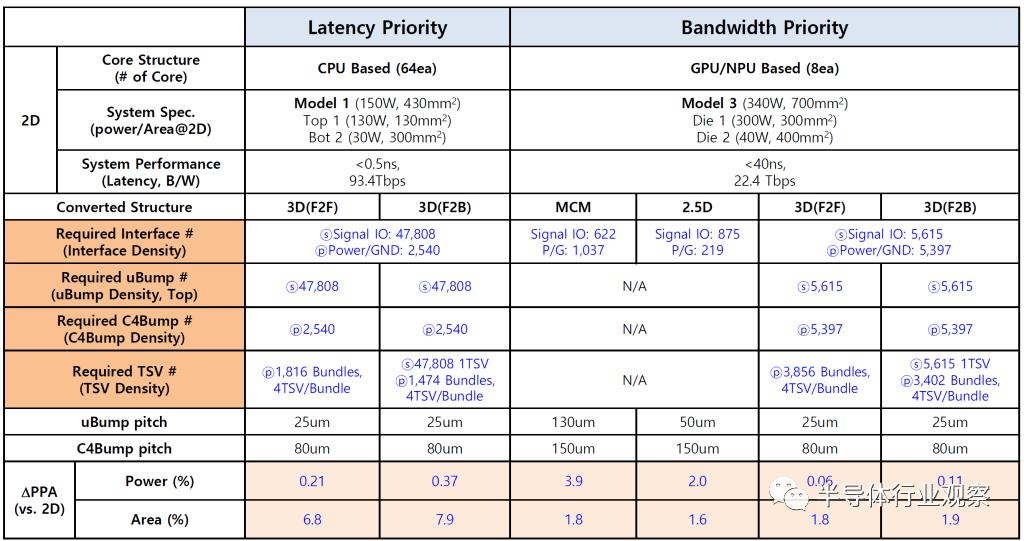
用于 HPC 和 AI 的单片 2D 芯片的面积为 450平方毫米。它被切成薄片(sliced up)并使用先进的封装将其粘合在一起。MCM 变体的功耗增加了 2.1%,芯片面积增加了 5.6%。2.5D设计,功率提升1.1%,面积增加2.4%。3D 设计的功率增加了 0.04%,但面积增加了 2.4%。这些结果当然是理想的,在现实世界中,与布局规划和布局问题相关的开销会更多。
SK 海力士 Wafer On Wafer 混合键合 DRAM
ASE 共封装光学器件
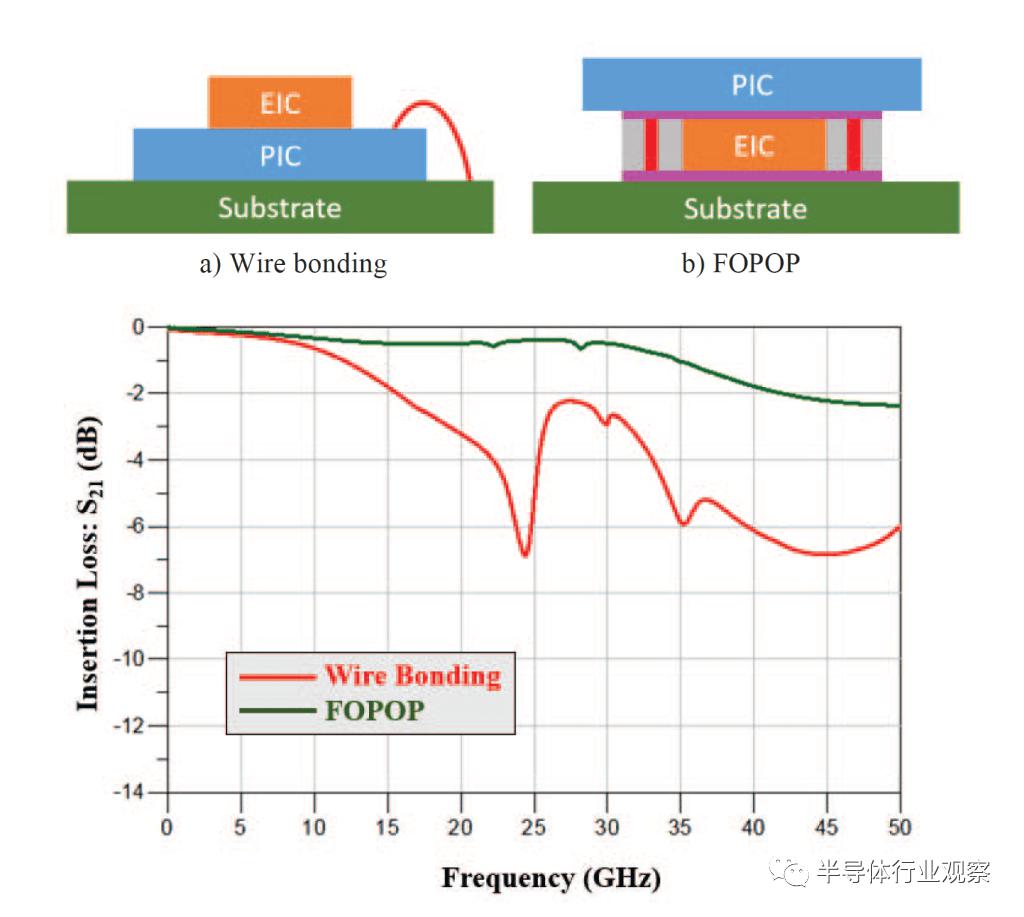
引线键合一直是 100G 一代产品的主要技术,但随着我们过渡到 400G 和 800G 代,它开始成为瓶颈。这是其他公司一段时间以来一直在进行的过渡,例如英特尔和 Fabrinet 已停止将 PIC 和 EIC 与最近几代产品进行引线键合。思科也已经从引线键合转向倒装芯片,今年他们甚至展示了使用 TSV 的 3D 组装,这比 ASE 展示的要先进得多。
ASE 论文总体上讨论了光学制造的独特挑战,包括contamination processes 的差异以及所使用的独特切割和蚀刻技术。晶圆厂后的晶圆工艺也不同,例如凸点下金属化和硅等。还讨论了独特的测试要求。ASE 进入光学制造领域还有很长的路要走,但重要的是要继续关注它们,将其视为电信和数据中心市场光学组装和封装领域潜在的非常有能力和可怕的新进入者。
超薄die的 Xperi Die Handling
Tokyo Electron Wafer on Wafer Hybrid Bonding
索尼领先的 1 微米间距混合键合
他们于 2017 年首次在大批量产品中交付该技术。他们目前每年交付数百万个 CMOS 图像传感器,采用 6.3 微米间距混合键合,堆叠 3 个裸片,而其他人的间距和体积要小得多。索尼的产品完全是晶圆对晶圆的混合键合。今年索尼推出了 1 微米间距面对面混合键合和 1.4 微米面对面混合键合。索尼目前使用面对面和面对面的混合键合。
索尼为何在混合键合上如此激进的简短解释是,索尼希望继续分解和堆叠图像传感器像素的功能,以捕捉更多光线,并能够捕捉更多数据并将其转化为实际照片和视频。
他们展示的技术非常有趣。所有混合键合工艺都需要极其平坦的表面,但在 CMP 工艺中铜和 SiO2 会以不同的速率被抛光掉。在大多数工艺中,这意味着铜会被磨掉到比 SiO2 低的水平。这通常称为dishing。这个过程必须精确控制,因为 SiO2 和铜的热膨胀系数也不同。台积电使用的一项技术是使用铜合金代替纯铜来控制凹陷程度并使 CMP 工艺更容易进行。
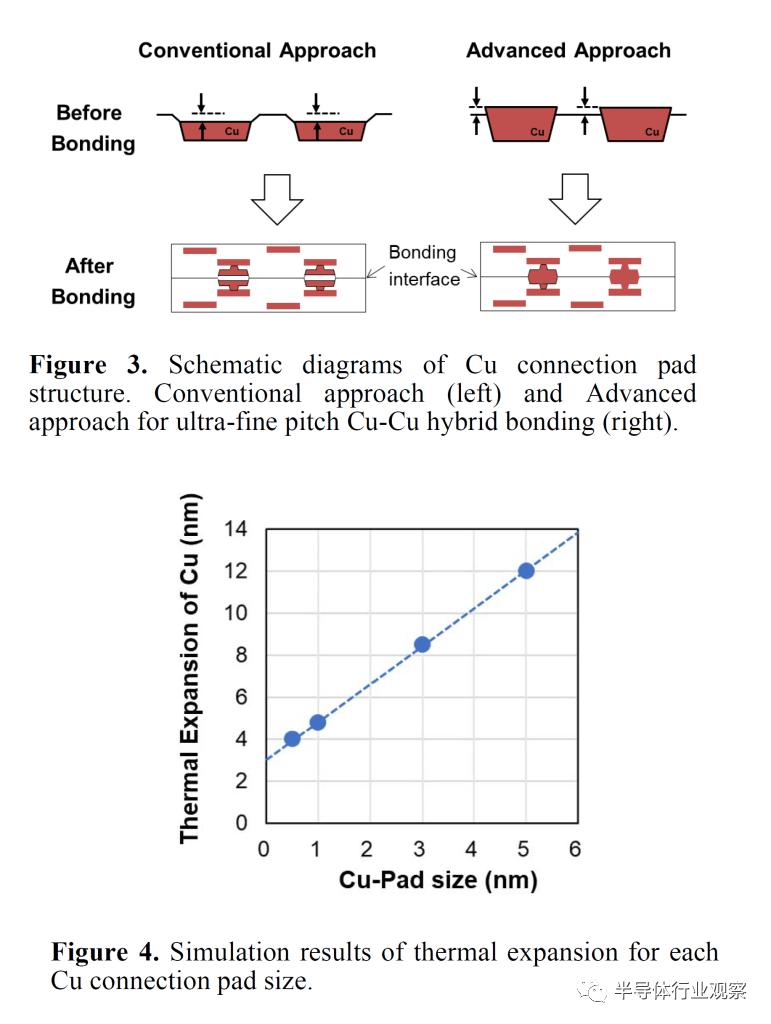
索尼,因为他们缩小到比行业其他公司小得多的间距,所以提出了相反的策略。在他们的先进方法中,SiO2 比铜被抛光得更远。这需要完全不同的专有 CMP 工艺。

索尼还通过改变 ECD 工艺中的晶粒尺寸实现了对铜的类似控制和突出。
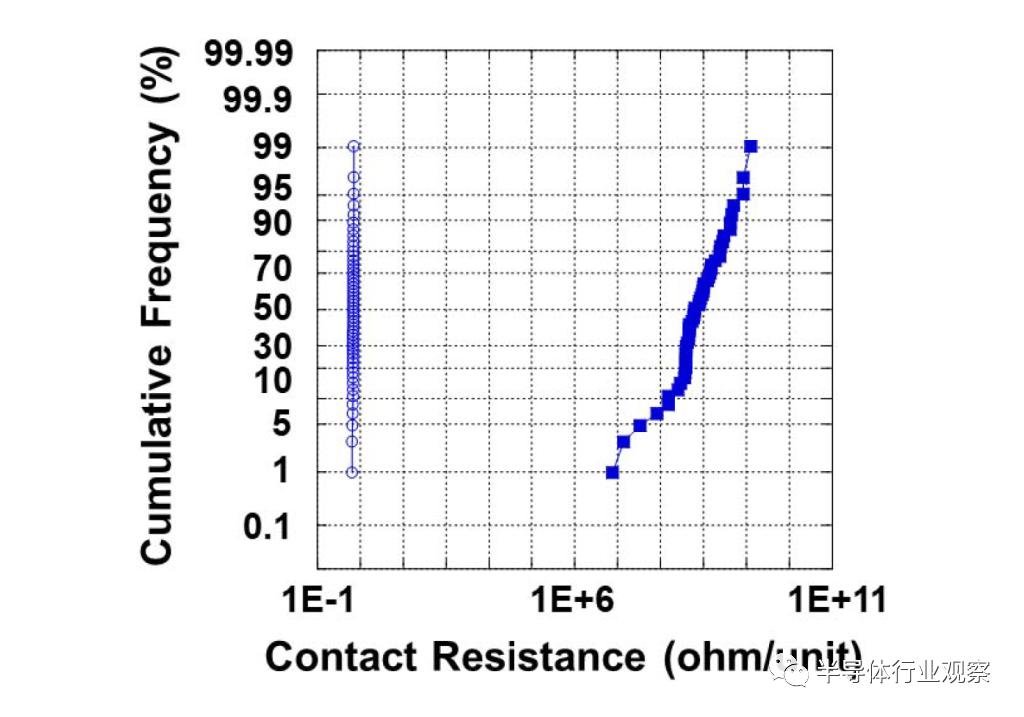
结果令人难以置信。与传统工艺相比,接触电阻提高了多个数量级。这是在 200,000 个菊花链(daisy chained) Cu-Cu 连接上进行测试的。这些是 1 微米面对面键合的结果,但 1.4 微米面对面粘合也显示出令人印象深刻的结果。
AMD Zen 3 上的 V-Cache SoIC 混合键合
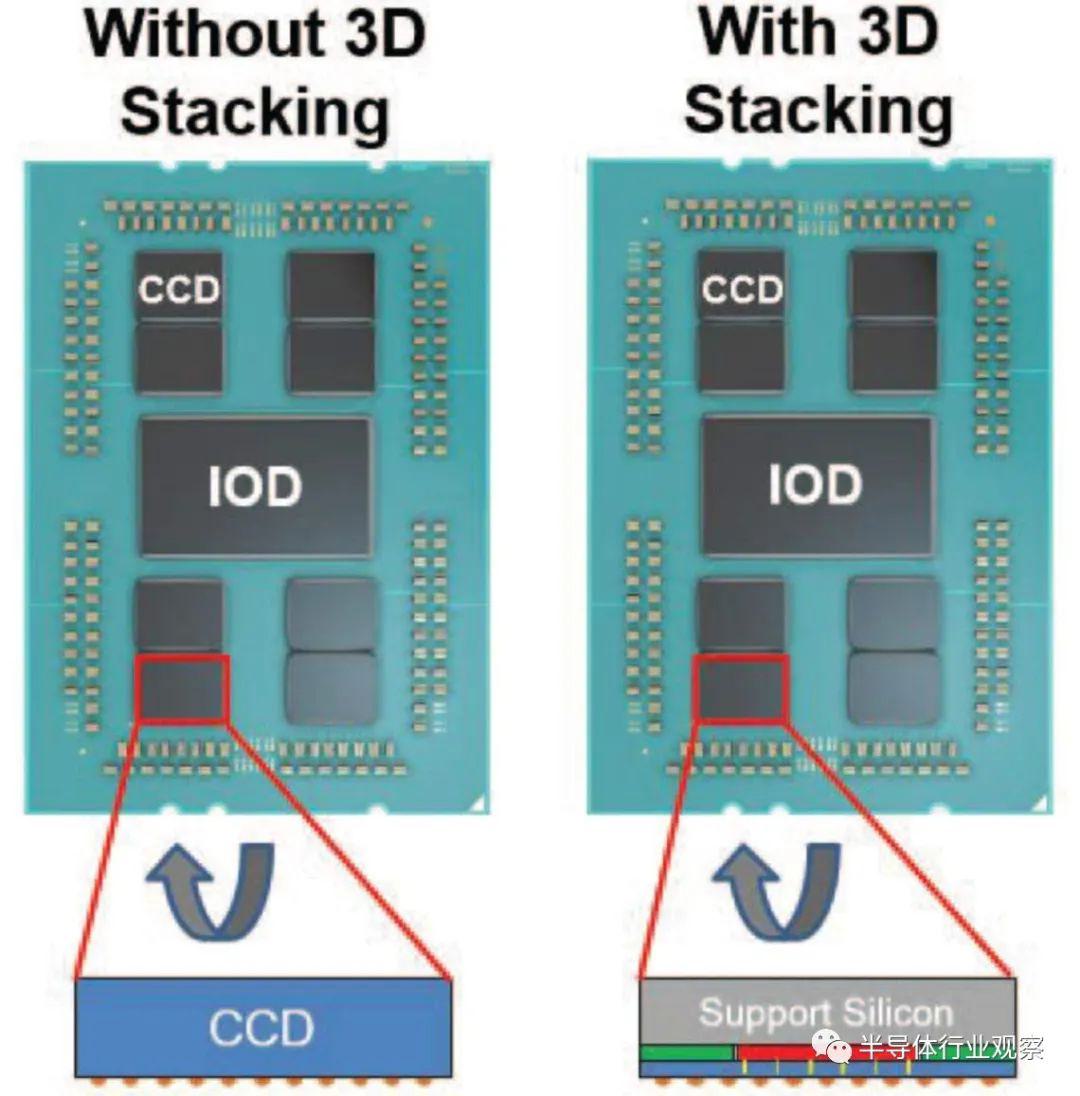
v-cache 的物理结构非常有趣。AMD 和 TSMC 不仅是 CPU CCD 小芯片,顶部还有 SRAM 小芯片和支持小芯片,而且还在整个组件的顶部有最后的第 5 块支持硅片。这种结构由IBM 的 Tom Wassick独立证实。
起初,这似乎是在浪费额外的硅,但这样做是因为台积电的混合键合工艺需要减薄的裸片。需要最后一块支撑硅片来为没有混合键合 SRAM 的标准 CCD 提供最终的芯片组件刚度和等效高度。
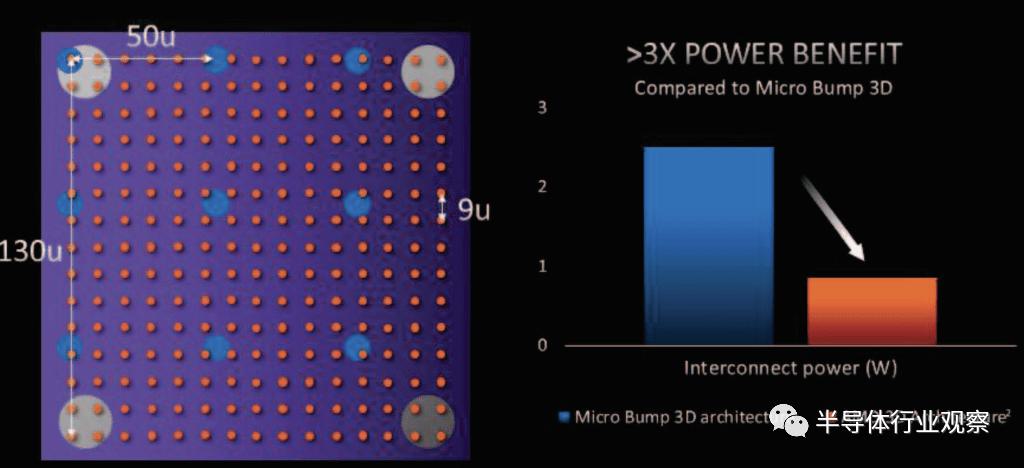
AMD 将 9 微米间距混合键合与 36 微米间距微凸块 3D 架构进行了比较。
AMD 指的是将用于 Ponte Vecchio GPU 和 Meteor Lake CPU 的 Foveros。AMD 声称,由于 TSV 和接触电容/电感更低,互连能效提高了 3 倍,互连密度提高了 16 倍,信号/电源完整性也更好。奇怪的是,他们使用 9 微米间距作为比较。这是一个不诚实的比较,因为TechInsights发现 V-Cache 的生产版本是在 17 微米间距上完成的。这种音调上的放松会减少所呈现的一些优势。
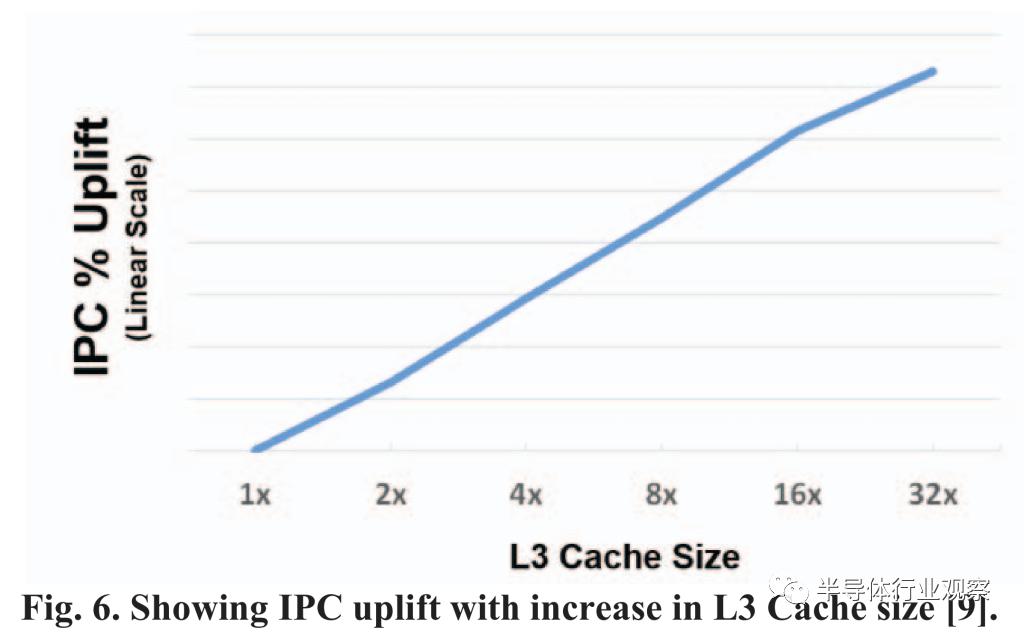
这张图表很有趣,尽管非常笼统。Zen 3 有 32MB 的 L3 Cache,V-Cache 为每个小芯片增加了 64MB。目前只堆叠了 1 个小芯片,这导致 IPC 的大范围增加。我想知道 AMD 使用什么模拟和基准测试来获得这个 IPC % Uplift 数据。AMD 还展示了一些与可靠性相关的数据,这表明在正常电压下没有问题。
联发科网络 SOC 可靠性
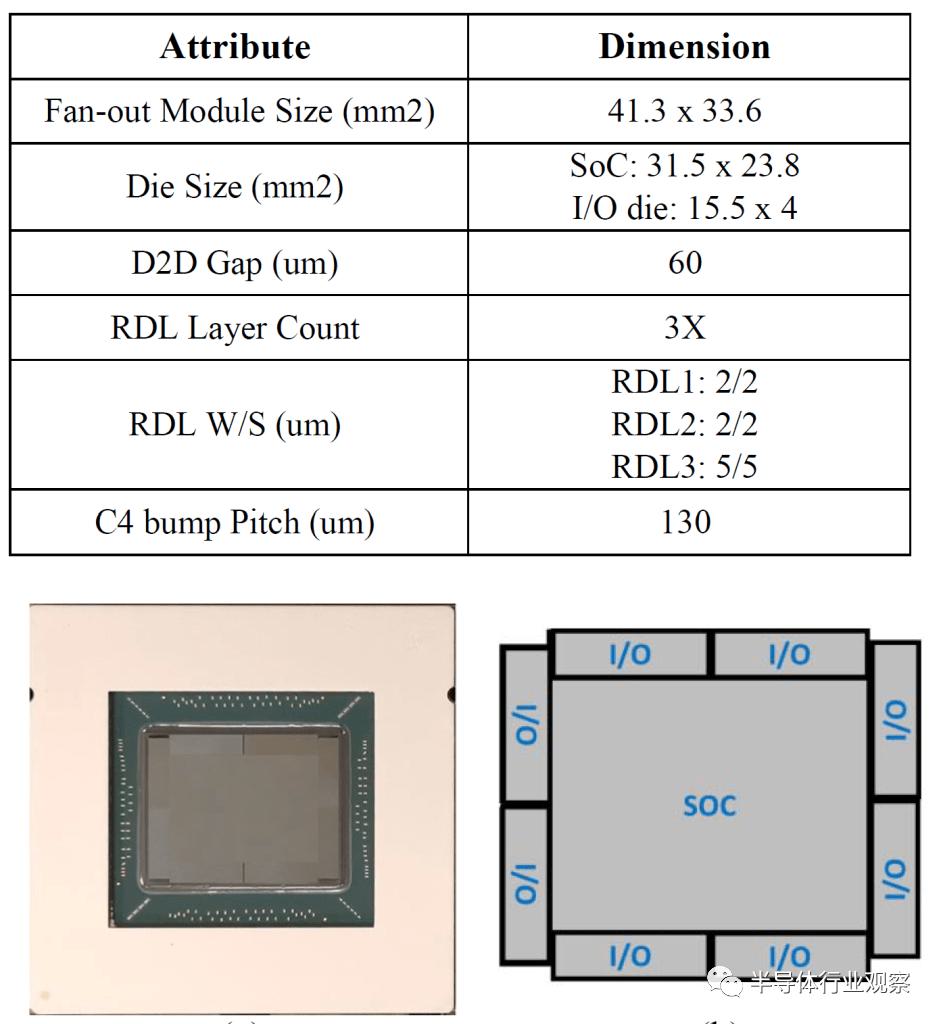
联发科也没有直接说明,但我们知道他们使用了台积电的 InFO-oS 技术。这篇论文讨论了温度、翘曲和其他可靠性问题,但有趣的是他们宣传了这款芯片。
来源:半导体行业观察